






 첼씨
첼씨

HBM의 경우 게임용에서는 거의 체감 성능이 없고,
빅 데이터와 AI 병렬 데이터 처리에서 많이 사용될것으로 기대 되는데,
삼성과 SK하이닉스에서 HBM 16단 스택으로 쌓아 올린것을 개발중이고 곧 상용화 한다고 하지만,
엔비디아에서 테스트를 해봤는데 발열을 잡을수가 없었지.
사실 개발 할 가치가 없다고 봐야돼.
HBM은 그런식으로 접근하면 혁신에 다 가 갈 수 없어.
앤비디아 CEO 젠슨황이 HBM 삼성 설계를 재주문 했다고 하는데,
16단으로 쌓아올린게 무지에서 이루어졌다고 봤기 때문일수도있지.
HBM 4096단으로 올린것과 같은 성능을 가진 HBM 4096단을 1년안에 양산이 가능한데,
아니, 40960단, 409600단과 같은 성능을 가진 HBM을 만들수도 있어.
당장이라도 말이지.
왜냐면 HBM은 같은 칩셋의 쌓아 올린것에 불과하기 때문이야.
슈퍼 컴퓨터처럼 병렬로 이어 붙이기만 하면 되는 문제인데,
GPU와 HBM을 분리하고, HBM을 병렬로 이어 붙이기만 하면 기하급수적으로 성능을 높일수있지.
발열 문제부터 전력 공급까지 손쉽게 해결이 가능해지는거야.
SLI를 생각하면 되는데, GPU에 HBM과 결합하는 부분을 만드는거지.
램 슬롯처럼 GPU와 HBM을 결합하게 되면 하나의 그래픽 카드가 만들어지는데,
이 슬롯 한개에 I/O 입출력단자를 204,800개로 만드는거지.
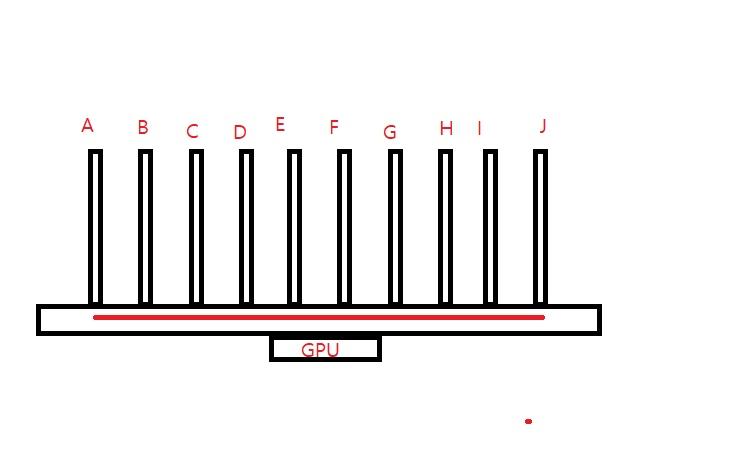
GPU 1개 슬롯당 204,800 I/O의 입출력 단자가 A~J까지 10개가 차있고,
GPU에는 총 2,2048,000개의 I/O 입출력 단자가 있는데,
A부분에서 204,800 I/O 입출력 단자가 100개로 나뉘어서 1개당 1024개의 I/O 입출력 단자로 4단의 HBM으로 연결되는거야.
4단의 HBM이 100개가 양면으로 있으닌깐, 입출력 단자는 1개의 슬롯당 204,800개가 할당 되겠지.
10채널을 전부 사용하게 되면 O/O는 2,048,000개가 되고, HBM 8000단급 성능을 내는거지.
HBM의 램에서 최대 적층은 4층인데, 4층보다 더 올리는것보다 슬롯을 추가해서 촘촘하게 만들면 되는거야.
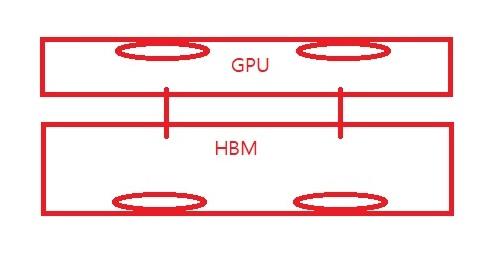
이거는 외형의 모습이야.

HBM 메모리칩 양옆에 4단으로 HBM이 100개씩 장착되어있는거야.
10개닌깐 8000단 HBM급이고, HBM에 각각 보조 전원을 연결하고, 쿨러를 결합하는거지.
GPU와 HBM이 연결되어있는데, HBM 안에 메모리 슬롯이 10개가 껴있는지,
1개만 껴있는지에 따라서, 실질적 성능이 달라지고 대역폭이 달라지는거야.
GPU 부분에 2개의 대형 팬 쿨러가 장착되어있고,
아래 HBM에도 대형 팬 2개의 쿨러가 장착되고, 보조 전원을 연결하는거지.
거리가 멀어지면서 지연 속도는 생기겠지만, 클럭을 높이면 되는 문제고,
10채널로 대역폭이 기하 급수적으로 높아져서, AI와 빅데이터용으로 적합한거야.
발열을 잡기 위해서, HBM에서 전류가 통하는곳에는 비전도성 서멀구리스를 바르고,
전류가 흐르지 않는곳에 전도성 서멀구리스를 발라,
열전도율을 최적화 해서, 쿨러를 통해 열을 방출하는거지.
써멀구리스로 하지 않고, 열전도율이 높은 물질로 납땜을 해도 되는 문제야.
이렇게 만들면 GPU에 HBM를 장착 조립해서 설치하면 되고,
GPU에 HBM을 장착해 끼우는 방식으로 만들어지는거지.
램 슬롯 채널을 늘리거나, HBM을 길게 만들고, HBM에 I/O 입력단자를 더 많이 넣어서,
용량은 줄이고 대역폭을 늘릴수있어. GPU 슬롯에 HBM 메모리만 장착해도 돼,
지금 당장이라도 이렇게 분리 조립형으로 HBM을 설계하고 만들면 2048단,4096단급 HBM을 만들수 있으며,
10만단위, 100만 단위의 HBM도 만들수도있고, 발열도 완벽하게 잡아낼수있는거지.




